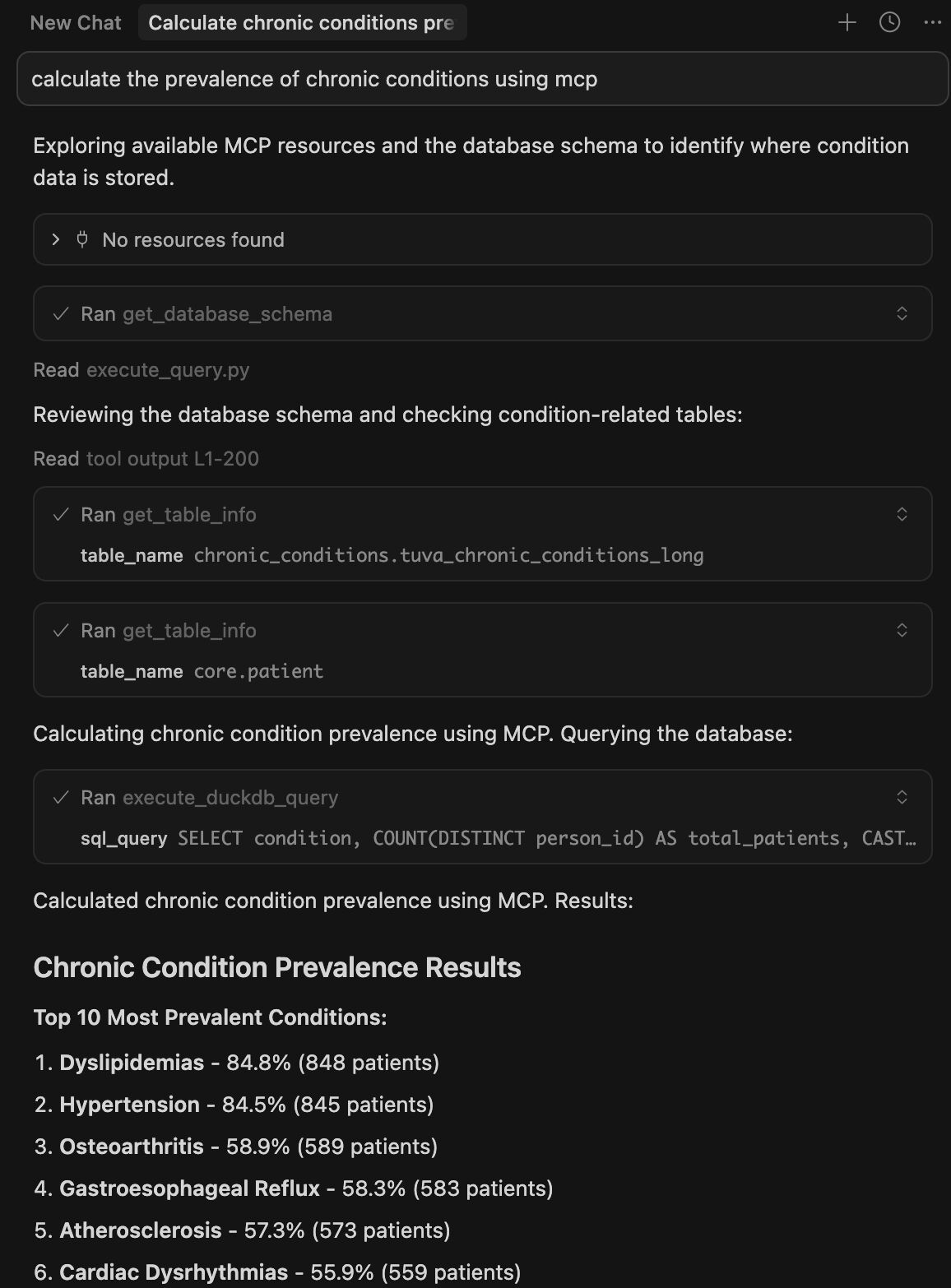
Inspired by researchers who built a MCP server for MIMIC-IV data, I wanted to see how a MCP server would fair with performing Q&A on healthcare data. Thankfully, I was able to tinker with Tuva Health’s open-sourced demo repository built with synthetic claims on DuckDB, and was pleasantly surprised to see that with three simple tools (get_database_schema, get_table_into, and execute_sql_query) I was able to ask the database some simple questions and get some accurate results!
Unsurprisingly, the MCP server struggles with more complex queries (i.e., queries that require multiple SQL table joins) in this initial first pass, but nonetheless was able to generate a few interesting queries that I did not think of before. This made me think of a few questions for my next iteration:
-
How can I provide more context to get more accurate answers? Is there such a thing as too much context?
-
How do you benchmark the performance of an MCP server? Is it truly possible to build an “expert-generated” answer sheet to grade the performance of the MCP server?