As proprietary models (e.g., GPT-5.2, Claude Opus 4.5) continue to improve and re-define what is state-of-the-art, it’s been equally exciting to see local models improve drastically in capabilities and crush “older” benchmarks. Admittedly, I haven’t played around with open-weight models since 🦙 Llama was a community favorite (but not anymore), so I was excited to once again hear my laptop fans kick into full gear and (mentally) feel better about the costly capital expenditure of my Macbook Pro (the November 2023 M3 Pro with 18GB RAM, to be exact).
Setting up the local model
I wanted to be able to set something up quickly for experimentation, so my main requirements were (1) something that I could setup with relatively little pain (2) something that would be compatible with Apple Silicon chips.
After some quick research, I decided to go with Ollama for its simplicity and docker-like interface, and picked two open models qwen2.5:7b-ctx32k and gpt-oss-20b-ctx32k to compare against claude-sonnet-4-5 and gpt-4-turbo.
The importance of applied benchmarks
While the data scientist in me would love to have set up some regression-based analysis, I think it’s pretty hard to have an apples to apples comparison between models as each model is optimized towards different use cases (e.g., coding agents vs general Q&A) + comes in different shapes & sizes. I found this Docker blog post on evaluating local LLM tool calling to be pretty insightful, with the main takeaways being: (1) which model can answer the prompt correctly using the provided tools (2) with the least amount of tool invocation?
Here’s a simple scoring rubric that I ended up going with:
| Criterion | Description |
|---|---|
| Pass or Fail Response | Does the outputs match the “golden” SQL query provided by Tuva? |
| Number of Tools Invoked | How many tools were invoked? In other words, did it take a lot of tokens just to answer a simple question? |
| Partial Credit? (Y/N) | If I was a nice grader who didn’t have to mark 800 exams, would I award a partial score? |
Before a question was called, I appended this simple prompt to instruct the LLM:
Tool dependency order:
get_database_schemamust be called before any other tool if schema is unknownget_table_infomust be called beforeexecute_querywhen columns are uncertainexecute_queryis only allowed after schema and table details are confirmedWorkflow:
- Identify missing information
- Call the appropriate tool
- Validate assumptions
- Then proceed
I then fed the following questions, one at a time:
Question Bank
| What is the prevalence of Tuva Chronic Conditions? Give me a breakout by condition |
| What is the count of ED visits by CCSR Category and Body System? |
| What is the average CMS-HCC Risk Score by Patient Location? |
| What is the overall readmission rate? |
| What is the healthcare quality measure performance? Provide a breakdown by performance rate |
| What is the distribution of chronic conditions? I want a breakdown of how many patients have 0 chronic conditions, how many patients have 1 chronic condition, how many patients have 2 chronic conditions, etc. |
| What is the total medicaid spend broken down by member months?1 |
| For quality measures, can you give me a breakdown of exclusion reasons and the count by measure? |
| What is the 30-day readmission rate by MS-DRG? Give me the MS-DRG description as well |
1 This turned out to be an unintentional mistake on my end while copying and pasting. The Tuva Project only has sample Medicare data, so I ended up using this question to evaluate whether the model hallucinated or not.
🏆 Results
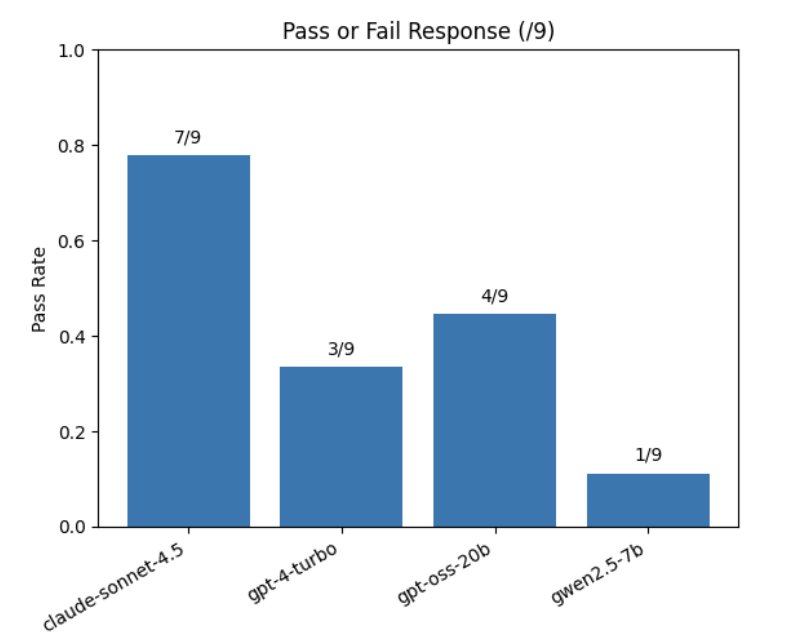
| Model | Partial Credit Awarded (/Failed Responses) |
|---|---|
| claude-sonnet-4.5 | 1/2 |
| gpt-4-turbo | 4/6 |
| gpt-oss-20b | 0/5 |
| gwen2.5-7b | 0/8 |
| Model | Average Number of Tools Invoked |
|---|---|
| claude-sonnet-4.5 | 7.1 |
| gpt-4-turbo | 3.8 |
| gpt-oss-20b | 8.4 (4.8 removing the one outlier where 35 calls were made) |
| gwen2.5-7b | 3.3 |
🤓 A Qualitative Analysis
I will preface by stating the obvious: benchmarking models based on 9 questions is far from a rigorous evaluation, but scoring responses manually and comparing between large(r) and small(er) models was quite an insightful exercise. With that disclaimer out of the way, here were some of my observations:
- Proprietary/larger models tend to be a lot more verbose, and really wanted to impress (what I mean is when given a relatively terse question, a model like Claude would generate all sorts of detailed analysis). Smaller models tend to used less tools, and were less capable at “unstucking” themselves
- That being said, constraints don’t necessarily have to be bad and I see a lot of potential in smaller models. In one rare example,
qwen2.5-7bactually tried to leverage model lineage (see my previous post) and was able to correctly reason that the downstream table would help answer the question (but sadly didn’t end up executing the SQL query using said downstream table) - Local models performed better than I thought! I was impressed with
gpt-oss-20b’s reasoning/tool-calling capabilities, which means that fine-tuning (smaller) LLMs on tool-use/agentic tasks will only get better and likely outperform larger models on domain-specific agentic tasks in the future