With the recent launch of ChatGPT Health and Claude for Healthcare — which promises the ability to “connect” your personal health data and chat with it — it reminded me of a paper I recently read titled “MIMIC-RD: Can LLMs differentially diagnose rare diseases in real-world clinical settings?” by health researchers at UIUC (led by Jimeng Sun, John Wu and team) that seems ever more relevant.
To test the efficacy of LLMs in rare disease diagnoses, the researchers used the MIMIC-IV clinical notes and specifically mined for “keywords” that might suggest a rare disease. Validated rare disease entities were then mapped to phenotypes from the Human Pheontype Ontology (sort of like the doctor noting that you have swelling, which is a symptom shared by many diseases). LLMs were then fed a list of a patient’s observed symptoms, and asked to predict a list of 10 most likely diseases based on the symptoms. The LLMs were scored as you would in a game of darts, that is, whether the rare disease falls within the top 1, 5, or 10 ranked predictions.
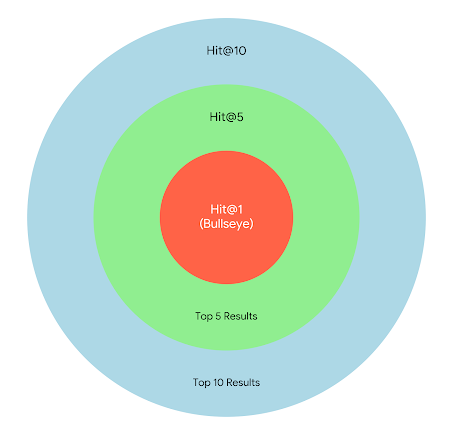
While the conclusion that (powerful) open-sourced LLMs underperform in differential diagnosis was unsurprising to me, I found the experiment setup to be very interesting, as the question wasn’t about how good the LLM is at mining for supporting evidence in clinical notes (in fact, LLMs are quite capable in looking for clues), but rather how good LLMs were in ranking the correct rare disease above other conditions (they weren’t). It also seems that the LLMs were evaluated based on already heavily preprocessed observed symptoms, so I would expect performance in the real-world to degrade with even higher “false positives” as data becomes noiser.
In conclusion, I don’t think we’re quite there in relying on LLMs to perform diagnosis, but I do think that announcements from OpenAI and Anthropic will spur an exciting drive towards building that “verification/context layer” for diagnosis, which will probably need to come from other modalities outside of text.
Supplemental Notes
- As a fun challenge for myself, I wanted to try and implement the clinical phenotype extraction/verification pipeline from the paper. You can read more about it here.